-
E-Mail-Adresse
service@h3c.com
- Telefon
-
Adresse
H3C, 466 Changhe Road, Binjiang, Hangzhou
Produktkategorien
Xinhua Three Technologie Co., Ltd.

H3C SeaSQL MPP verteilte Datenbank
VerhandlungsfähigAktualisieren am12/28
- Modell
- Natur des Herstellers
- Hersteller
- Produktkategorie
- Ursprungsort
Übersicht
Die Internetindustrie hat in den letzten zehn Jahren eine große Menge an Informationen und Daten angesammelt, die sich von langsamen zu schnellen Entwicklungen entwickelt haben und eine neue Berechnungsmethode für große Datenmengen erfordern. Die herkömmlichen Berechnungsmethoden sind nicht mehr ausreichend, um die Verarbeitung von großen Datenmengen zu bewältigen, und die Nachteile sind offensichtlich, neben den hohen Kosten ist es technisch schwierig, die Datenberechnungsleistungsindikatoren zu erfüllen, das Scale-up-Modell des herkömmlichen Hosts hat Engpässe, die SMP-Architektur (Symmetrical Multi-Processing, Symmetrical Multi-Processing) ist schwierig zu skalieren und kann nicht die massiven Datenberechnungsanforderungen an CPU-Berechnungen und IO-Durchsatz erfüllen. Vor diesem Hintergrund entstand die verteilte Datenbank H3C SeaSQL MPP mit einer leistungsstarken Leistungsanalyse für die Verarbeitung von Datenmengen auf PB-Ebene. H3C SeaSQL MPP basiert auf einer Shareless MPP-Architektur (Massive Parallel Processing), bietet gute Elastizität und lineare Skalierbarkeit, integrierte Parallel-Storage-, Parallel-Kommunikations-, Parallel-Computing- und Optimierungstechnologien, ist kompatibel mit SQL-Standards, verfügt über leistungsstarke, effiziente und sichere PB-Ebene strukturierte, halbstrukturierte und unstrukturierte Datenspeicher-, Verarbeitungs- und Echtzeit-Analysefähigkeiten, unterstützt gleichzeitig hybride Lasten, die OLTP-basierte Geschäfte abdecken, ermöglicht Kunden den geschlossenen Schleifen Business-Data-Insight-Geschäft, kann in der Enterprise Naked Machine oder in der Private Cloud bereitgestellt werden, unterstützt eine Vielzahl von Kernproduktionssystemen in verschiedenen Branchen, einschließlich Finanzen, Wertpapieren, Telekommunikation, Regierung, Fertigung, Transport und mehr.
Produktdetails
Systemarchitektur
Um Kunden aus allen Branchen bei der Bewältigung der Herausforderungen des Big Data-Zeitalters zu helfen, hat H3C eine leistungsstarke Big Data-Plattform entwickelt, die ein Computing-Framework mit Hadoop und MPP integriert, um Anwendern eine komplette Big Data-Plattformlösung zu bieten, einschließlich Datenerfassungstransformation, Storage-Computing, Analytics-Mining, Shared Exchange, BI-Darstellung und Operations-Management, um Anwendern zu helfen, massive Datenverarbeitungssysteme aufzubauen, den inhärenten Wert der Daten zu entdecken und neue Marktchancen zu erschließen.
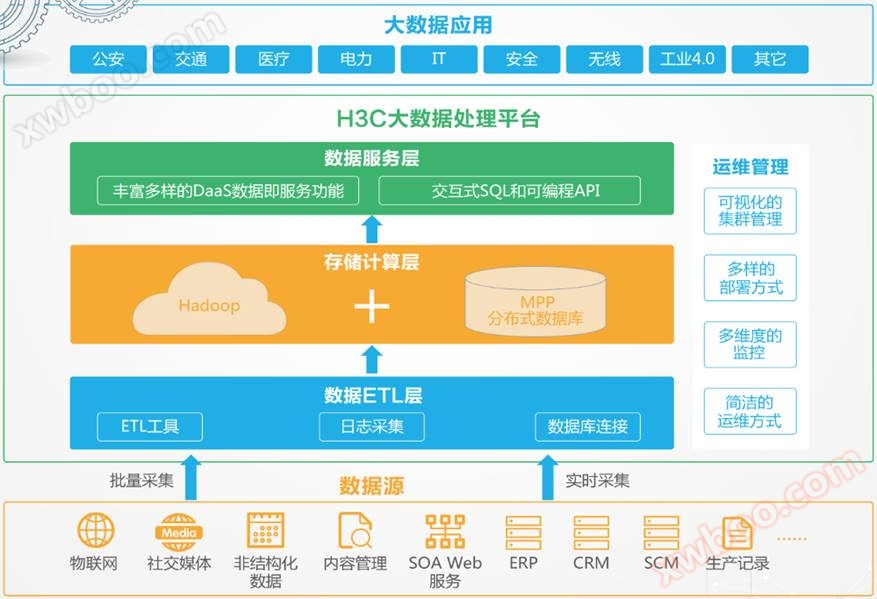
SeaSQL MPP unterstützt sowohl die Bereitstellung lokaler physischer Maschinen als auch die Bereitstellung in einer privaten Cloud, wobei die Datenquellen lokal gespeichert werden können. HDFS、 Cloud-Speicher oder andere relationale Datenbanken wie Oracle, MySQL usw. werden mit ETL-Tools oder Kafka in SeaSQL MPP-Datenbanken integriert. Die verteilte SeaSQL MPP-Datenbank basiert auf einer massiven parallelen Architektur ohne gemeinsame Nutzung und verfügt über eine Datenverarbeitungskapazität auf PB-Ebene. Der Kern basiert auf dem PostgreSQL-Kern und wurde erheblich optimiert, bietet einen leistungsstarken Abfrageoptimator und ist vollständig kompatibel mit SQL. Auf der Schnittstellenebene bietet SeaSQL MPP neben der Standard-JDBC/ODBC-Schnittstelle auch Schnittstellen für die häufig verwendete Programmiersprache Python/R/Java/Perl/C sowie Schnittstellen für die Machine Learning-Bibliothek MADLib, Volltextsuche und PostGIS für den Aufruf auf der Anwendungsebene.

SeaSQL MPP ist eine verteilte Architektur mit hoher horizontaler Skalierbarkeit, die Tausende von Knoten miteinander verbindet und Tausende von CPUs unterstützt. Seine leistungsstarken Datenverarbeitungs- und Rechenleistungen eignen sich für folgende Szenarien:
• Geeignet für analytik orientierte Anwendungen wie den Aufbau von ODS/EDW auf Unternehmensklasse, Datenmarkte usw.
• Geeignet für Anwendungen, die große Datenmengen verarbeiten müssen, wie Data Warehouse, Business Intelligence usw.
• Analyse und Data Mining für Offline-Daten wie Kundenverhaltenanalyse, Personenporträte, Verhaltensprädiktive Modellierung usw.
Funktionen
H3C SeaSQL MPP ist eine auf PostgreSQL basierende verteilte Datenbank, die eine Shared-Nothing-Architektur verwendet, Host, Betriebssystem, Speicher und Speicher sind selbstgesteuert und keine Freigabe gibt. Die wichtigsten Merkmale der H3C SeaSQL MPP-Datenbank sind:
• Parallele Architektur.
· Unterstützt sowohl Zeilen als auch Listen. Jede Tabelle oder Tabellenpartition kann vom Administrator entsprechend den Bedürfnissen der Anwendung jeweils gespeichert und komprimiert werden.
Unterstützt verschiedene Komprimierungsmethoden, einschließlich Zlib, RLE usw.
· Unterstützung für mehrstufige Partitionstabellen, Partitionen unterstützen verschiedene Muster, einschließlich Bereiche, Listen usw.
Unterstützung von Indexen wie B-Baum, Bitmap und GiST.
Authentifizierungsmechanismen unterstützen verschiedene Methoden, einschließlich LDAP und Kerberos.
Erweiterte Sprachunterstützung: SeaSQL MPP unterstützt die Implementierung benutzerdefinierter Funktionen in mehreren beliebten Sprachen, einschließlich Python, R, Java, Perl, C / C ++ usw.
• Geoinformationsverarbeitung: Durch die Integration von PostGIS unterstützt SeaSQL MPP die Speicherung und Analyse von geografischen Informationen.
Integrierte Datenmining-Algorithmusbank: Mit der MADlib-Algorithmus (jetzt das Apache-Inkubationsprojekt) können Dutzende gängiger Datenanalyse- und Mining-Algorithmen in SeaSQL MPP-Datenbanken eingebaut werden, einschließlich Logische Regression, Entscheidungsbaume, Zufallswalder usw. Sie müssen keinen Algorithmus schreiben, alle Algorithmen können über SQL verwendet werden.
Textsuche: SeaSQL MPP unterstützt eine effiziente und flexible Volltextsuche. Zusammen mit MADlib können parallele Textanalysen und -mining durchgeführt werden.
· Hochleistungsstarke Ladung mit MPP-Technologie, die eine Ladeleistung auf Petabyte-Ebene bietet.
• Optimierung der Abfrage von Big Data-Workflows.
• Multiforme Datenspeicherung und -ausführung.
Erweiterte Fähigkeiten für maschinelles Lernen basierend auf Apache MADlib.
Unterstützung für SQL 92 ANSI/ISO, SQL 99 ANSI/ISO, SQL 2003 ANSI/ISO, SQL 2006 ANSI/ISO Standards, Unterstützung für internationale Schnittstellenspezifikationen wie C API, ODBC, JDBC, Unterstützung für DDL, DML, DCL Syntax, Unterstützung für grundlegende Datentypen, grundlegende Integritätsbeschränkungen, grundlegende Tabellenverwaltung, Suchkriterien, Tabellenverbindungen, Subabfragen, Einfügen, Ändern, Löschen, Transaktionssteuerung.
Vorteile
Cloud-Bereitstellung
SeaSQL MPP unterstützt die Bereitstellung der CloudOS 5.0 Cloud-Plattform und unterstützt die Bereitstellung in der Cloud. Die Benutzer können alle Ressourcen über die CloudOS-Oberfläche einheitlich verwalten und das Planungsmanagement einheitlich verwalten, um die zugewiesene Ressourcenverwaltung flexibel zu verwalten und die gesamte Ressourcennutzung zu verbessern.

Erweiterung ohne Unterbrechung
Die SeaSQL MPP-Datenbank kann auf zwei Arten skaliert werden: Host-Skalierung und Instanz-Skalierung. Die Skalierung erfolgt durch die Aktualisierung der Metadaten der Systemtabelle, ohne die Datenbank zu stoppen, und der Jump Consistent Hash-Algorithmus nach der Skalierung der Datenbank reduziert die Bewegung der Daten während der Datenwiederverteilung erheblich.
Reihengemischter Speicher
Die SeaSQL MPP-Datenbank bietet verschiedene Arten von Speichermodellen: Zeilen-, Spalten- und Reihengemischter Speicher, mit dem Sie ein Speichermodell für Ihre Daten anpassen können.

OLAP Funktionen
SeaSQL MPP bietet umfangreiche OLAP-Funktionen wie Rollup, Cube, Fensterfunktionen, rekursive Operationen usw. zur Unterstützung komplexer Analyseoperationen, die sich auf die Unterstützung von Entscheidungsträgern und Führungskräften konzentrieren. Die Analysten können komplexe Abfragen mit großen Datenmengen schnell und flexibel bearbeiten, so dass sie genau die Geschäftsbedingungen ihres Unternehmens verstehen, die Bedürfnisse ihrer Kunden verstehen und die richtigen Pläne entwickeln können.
Mehrere Mieter
Die Multitenant-Funktion der SeaSQL MPP-Datenbank kann eine Datenbank auf mehrere Mieter unterteilt werden, die physischen Ressourcen verschiedener Mieter sind voneinander isoliert, und die Multitenant-Funktion spiegelt hauptsächlich die folgenden Vorteile wider:
Verschiedene Mieter haben unterschiedliche Anforderungen an physische Ressourcen, und die einzelnen Ressourcen werden voneinander isoliert, um zu verhindern, dass bestimmte Mieter die Ressourcen anderer Benutzer in den Höhepunkten des Geschäfts ergreifen.
Die Daten zwischen den Mietern werden voneinander isoliert, was die Datensicherheit erhöht.
Wenn die Systemressourcen frei sind, können CPU- und Speicherressourcen flexibel verwendet werden, wenn die Ressourcen beschäftigt sind, werden die Ressourcen zwischen den Mietern gemäß den Parametern eingeschränkt, um die Ressourcennutzung des gesamten Systems zu verbessern.
Starke parallele Ladefähigkeit
Die Leistungsindikatoren für den Import von Daten spielen eine wichtige Rolle für die Nutzungserfahrung von Data Warehouses, SeaSQL MPP-Datenbanken können die Ressourcen aller Knoten im gesamten Cluster verwenden, während sie Daten laden, und die Ladeleistung steigt linear, wenn die Anzahl der Knoten steigt, und die Ladegeschwindigkeit von Daten in einem großen Cluster kann bis zu 20 TB / Stunde erreichen.
Integrierte MADLib Machine Learning-Bibliothek
MADlib ist nicht für Programmierer, sondern für Datenbankentwicklung oder DBA ausgerichtet und kombiniert die einfache Verwendung von SQL mit komplexen Algorithmen für Data Mining, um die Vorteile und Eigenschaften beider zu nutzen und die Entwicklereffizienz erheblich zu verbessern.
MADlib bietet Benutzern Funktionen, die in SQL-Abfrageanweisungen aufgerufen werden können, die nicht nur grundlegende lineare algebraische Berechnungen und statistische Funktionen umfassen, sondern auch gängige, fertige Machine Learning- oder Data Mining-Modellfunktionen. Der Benutzer braucht kein tiefes Verständnis der Details der Programmimplementierung des Algorithmus zu haben, sondern muss nur die Verwendung der Funktion verstehen, was die Entwicklungseffizienz erheblich verbessert und die Entwicklungskosten spart.

Integrierte PostGIS-Datenverarbeitung
PostGIS ist eine Erweiterung des objektbezogenen Datenbanksystems PostgreSQL, das das PostgreSQL-Datenbankmanagementsystem in eine räumliche Datenbank umwandelt, indem es Unterstützung für räumliche Datentypen, räumliche Indexe und räumliche Funktionen hinzufügt.
SeaSQL MPP integriert die PostGIS-Raumdatenbank zur vollständigen Integration von Raumdaten und Objektrelationsdatenbanken, um den Übergang von GIS-zentrierten zu datenbankzentrierten zu ermöglichen. Auf diese Weise benötigen Benutzer keine speziellen GIS-Datenmotoren, um die Raumdaten zu verarbeiten und zu manipulieren, und Anwendungen können die Raumdaten einfach über die SQL-Sprache manipulieren.
Transparente Verschlüsselung
Das SeaSQL MPP Transparent Encryption Modul ermöglicht eine Verschlüsselung der gesamten Datenbank, die für den Client völlig unbewusst ist. Verschlüsselung der Daten beim Schreiben von Datenblöcken auf die Festplatte; Entschlüsseln Sie die Daten, wenn sie von der Festplatte gelesen werden. Sie können sicherstellen, dass die auf der Festplatte gespeicherten Daten immer verschlüsselt sind und dass die darin enthaltenen Klartextdaten nicht gelesen werden können, selbst wenn der Festplatteninhalt abgerufen wird. Gleichzeitig ist die geschäftliche Ebene völlig unbewusst über die Verschlüsselung und erfordert keine Anpassungsänderungen an die Verschlüsselung. Die Verschlüsselung erfolgt mit dem AES XTS-Verschlüsselungsmodus, um die Sicherheit der Datenverschlüsselung zu gewährleisten.
Datenentempfindlichkeit
Datenmaskierung, auch als Datenbleichung, Datendeprivatisierung oder Datenverformung bezeichnet. Es bezieht sich auf die Veränderung bestimmter sensibler Informationen durch Regeln zur Entempfindlichkeit, um einen zuverlässigen Schutz sensibler Datenschutzdaten zu erreichen. In Fällen, in denen Kundensicherheitsdaten oder einige kommerziell sensible Daten betroffen sind, müssen Daten ohne Verstoß gegen die Systemregeln entworfen werden, um echte Daten zu modifizieren und Testanwendungen bereitzustellen, wie z. B. Personalausweissnummern, Handynummern, Kartennummern, Kundennummern und andere persönliche Daten.
Die SeaSQL MPP-Datenbank bietet eine Vielzahl von Möglichkeiten zur Entsensifizierung und nach der Definition der Entsensifizierungsregeln können Benutzer auf die Entsensifizierungsdaten auf zwei Arten zugreifen:
Statische Entempfindlichkeit:Wenn Sie sensible Informationen aus der Bibliothek entfernen, werden sensible Daten in der Datenbank nicht wiederhergestellt.
Dynamische Entempfindlichkeit:Wenn Sie sensible Informationen für bestimmte Benutzer blockieren, haben andere Benutzer, die nicht deaktiviert sind, weiterhin Zugriff auf die Rohdaten.
FDW Datenkonfederation
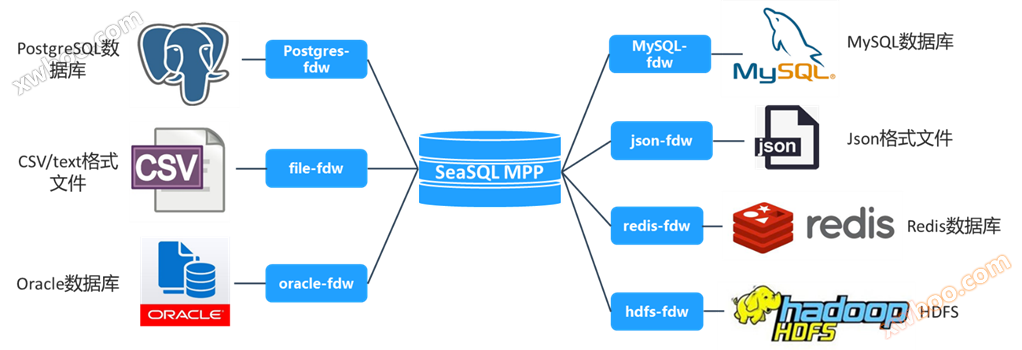
FDW ist die Implementierung des SQL-Standards SQL/MED (SQL Management of External Data). FDW bietet eine Reihe von einheitlichen öffentlichen Schnittstellen, die es Ihnen ermöglichen, die Erweiterungen in Kernteile wie Optimierung, Ausführung, Scannen, Updates und Statistiken mit SeaSQL zu integrieren, um externe Datenquellen direkt mit SQL-Anweisungen abzufragen und zu bedienen. Mit FDW für MySQL können Benutzer beispielsweise Daten aus einer MySQL-Datenbank direkt abfragen, sortieren, gruppieren, filtern, zusammenfügen oder sogar einfügen und aktualisieren, wie sie mit einer lokalen Tabelle arbeiten.
Je nach Datenquelle umfassen die FDW-Module, die SeaSQL implementiert: postgres_fdw、file_fdw、oracle_fdw、mysql_fdw、json_fdw、redis_fdw、hdfs_dfw, Wie in der folgenden Abbildung gezeigt:
Roaringbitmap Bitmap komprimieren
RoaringBitMap ist ein effizienter Bitmap-Komprimierungsalgorithmus, der die Effizienz des Bitmap-Speichers effektiv verbessert und das Problem behebt, dass sich seltene Bitmaps nicht an den seltenen Speicher anpassen. Bitmap-Bit-Berechnung ist ideal für die Berechnung von großen Datenbasen und wird häufig bei der Abgewichtung, Etikettenfilterung, Zeitreihen und anderen Berechnungen verwendet. Das gpdb_roaringbitmap-Plugin integriert die Roaringbitmap-Funktion in die SeaSQL MPP-Datenbank und bietet native Datenbankfunktionen, Operatoren, Aggregationen und andere Funktionen als Datentyp.




